2.2 Korkeusmallien maailmassa
Viikon aiheena oli tutustua korkeusmallien ominaisuuksiin ja hyödyntämiseen. Tasojen metatietoihin tutustuttiin tarkemmin ja korkeusdatan pohjalta selvitettiin potentiaalisia jokiuomia hydrologisella mallinnuksella. Lisäksi harjoiteltiin muutaman rasterityökalun käyttöä.
Korkeuden salat Kevon kanjonissa
Tällä kertaa tarkastelussa oli Kevon kanjoni Pohjois-Lapista. Varsinaisena aineistona toimi korkeusmalli ja tukena olivat maastokartta ja ortokuvat samalta alueelta. Ensimmäisenä tarkasteltiin korkeusaineiston ominaisuuksia tason metatiedoista. Ei ollut yllätys, että projisoituna koordinaattijärjestelmänä oli TM35FIN ja yksikköinä toimivat metrit. Spatiaaliseksi resoluutioksi osoittautui 2 metriä per pikseli ja itse rasterin koko oli 3000x3000 pikseliä, eli 36km2. Alueen korkeus vaihteli suurin piirtein välillä 145m ja 423m merenpinnan yläpuolella. Alla olevassa kuvassa korkeimmat alueet on merkitty ruskealla ja matalimmat alueet tummanvihreällä.

Korkeusaineisto kevon kanjonista
Seuraavaksi tehtiin jo edelliseltä kurssilta tuttu rinnevalovarjostu (Hillshade) ja korkeuskäyrät helpottamaan aineiston hahmottamista. Kun Hillshade-tasoa sekoittaa (blend) alempiin tasoihin, antaa se kartalle syvyyttä, kuten alla olevasta kuvasta huomaa.

Korkeusaineisto Hillshade-tason kanssa
Toisaalta Hillshade ei anna tarkkaa kuvaa korkeusvaihtelun koosta, vaan tähän toimivat paremmin korkeuskäyrät. Korkeusaineiston pohjalta luodut korkeuskäyrät vastasivat kohtuullisen tarkasti valmiin maastokartan korkeuskäyriä. Kuitenkin joissain kohdissa maastokartan käyrät olivat hieman tasaisempia, kun taas automaattisesti luoduissa käyrissä oli ehkä tarpeettoman paljon yksityiskohtia.

Automaattisesti luodut korkeuskäyrät osuvat tarkasti alla olevan maastokartan korkeuskäyriin

Tarpeettomia yksityiskohtia automaattisesti luoduissa korkeuskäyrissä
Korkeusmallin johdannaiset
Pehmeän laskun jälkeen oli aika tutustua korkeusmallin johdannaisiin; Slope- ja Aspect-analyyseihin. Nämä ovat työkaluja, joiden tuotokset tukevat muiden analyysien toteuttamista.
Slope on funktio, joka laskee rinteen jyrkkyyden rasterin eri kohdissa korkeusdatan avulla. (Holopainen et al., 2015, s. 62) Aspect puolestaan laskee rinteelle suuntatiedon. (Holopainen et al., 2015, s. 84)
Kevon alueella jyrkimmät rinteet olivat jopa 79° ja luonnollisesti tasaisimmat alueet olivat lähellä 0°. Alla olevassa kuvassa visualisoin tasaisimmat alueet vihreällä ja jyrkimmät alueet punaisella. Tämä toi mielestäni Slope-analyysin automaattisesti luomaan värimaailmaan hieman lisää informatiivisuutta.
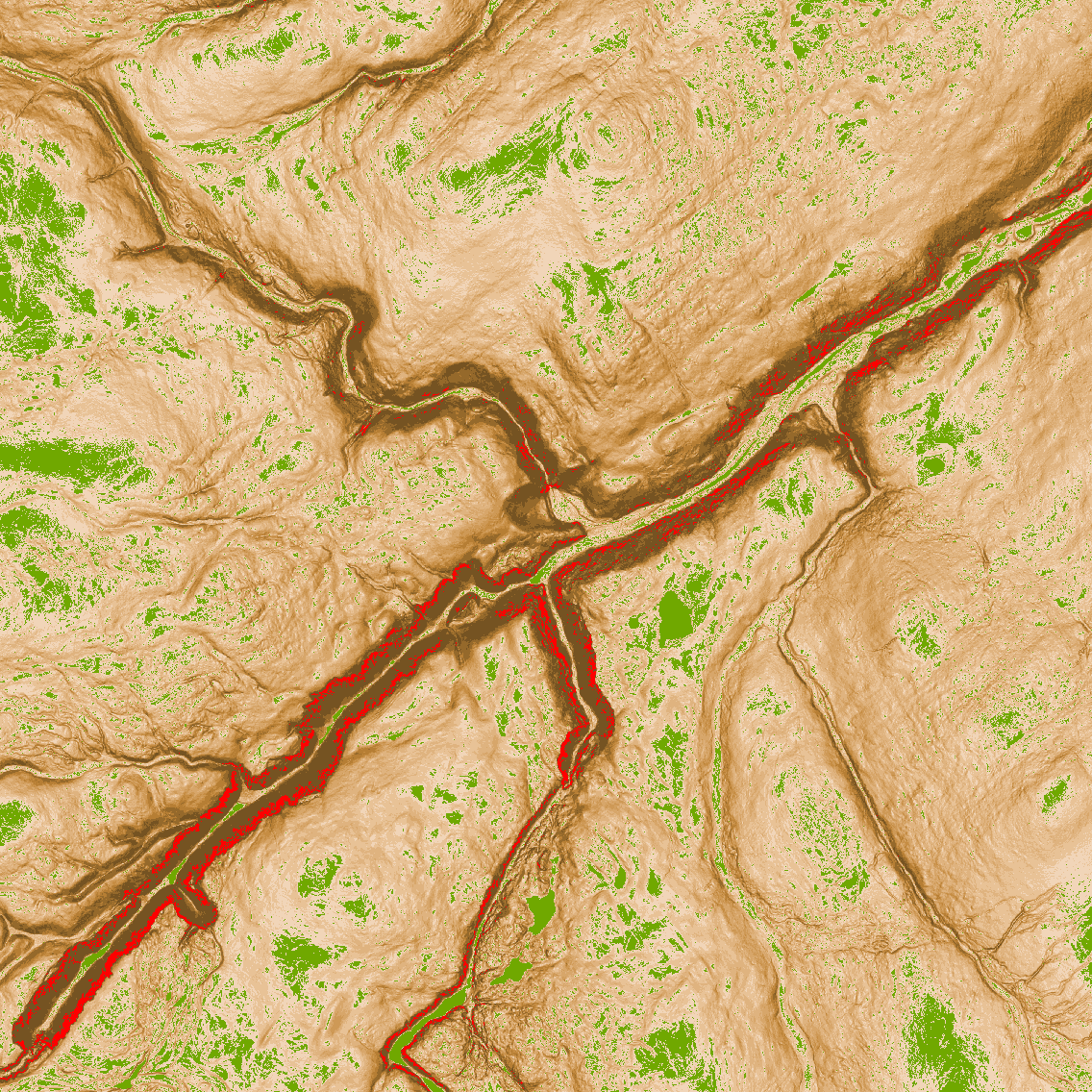
Tyylitelty Slope-analyysi Kevon kanjonin alueelta
Ilman värimuokkauksiakin laaksojen pohjat ja kanjonin rinteet on helppo tunnistaa, mutta lisäväri tuo paremmin esille muun muassa muutamat korkeammalla olevat lammet, jotka näkyvät hyvin myös ilmakuvissa.

Ilmakuvia Kevon kanjonista
Aspect-analyysi luo tason, jossa on rinteen suunta asteina ja jokaista ilmansuuntaa vastaavalle astevälille on annettu uniikki väri. Lopputulos on hyvin sekava ihmisen tulkittavaksi, mutta muiden funktioiden käyttöön erittäin hyödyllinen. Vaikka Aspect-tasoa ei olekaan varsinaisesti tarkoitettu itsessään tarkastelavaksi, vaan avuksi muita analyysejä luotaessa, voi myös sen hahmottamista helpottaa Hillshade-tason avulla.


Aspect analyysin tulos ja Hillshade-tasolla paranneltu versio
Hydrologinen mallinnus
| Hydrologisella mallinnuksella tarkoitetaan erilaisia analyysejä veden valumiseen liittyen. (Holopainen et al., 2015, s. 51) |
Ennen varsinaisia analyysejä visualisoitiin korkeusdatassa olevat kuopat, eli analyysien potentiaaliset umpikujat. Korkeusdatasta luotiin ensin Sink-työkalulla rasteri kaikista kuopista, joka edelleen muunnettiin vektoritasoksi Raster to Point -työkalulla.

Korkeusdatan kuopat visualisoituna pisteinä
Kuten visualisoinnista voi huomata kuopat olivat erityisesti “pakkautuneet” kanjoneihin, jotka ovat juurikin potentiaalisimpia uomien sijainteja. Kuopat oli siis täytettävä Fill-työkalulla, jotta hydrologinen mallinnus onnistuisi parhaalla mahdollisella tavalla. Kuopattoman korkeusmallin pohjalta luotiin virtaussuunta-rasteri Flow Direction -työkalulla
| Viikon harjoitusohjeissa ollut virtaussuunta ruudukko kiinnitti huomioni tietojenkäsittelytieteen opiskelijana. Ruudukossa ilmansuuntia kuvaavat numeroarvot olivat kahden potensseja, jotka tulevat hyvin tutuiksi binääri arvojen kanssa työskennellessä. Tästä heräsi hieman tangentille lähtenyt pohdiskelu suunta-datan luonteesta. Tieto on todennäköisesti tallennettu jokaista pikseliä vastaavaan kahdeksan bitin, eli yhden tavun, kokoiseen pakettiin. Tässä tietomuodossa tavun jokainen bitti vastaa yhtä ilmansuuntaa ja kaikkien bittien ollessa 0 ollaan tasaisella maalla tai tieto puuttuu. Tässä muodossa data on mahdollisimman yksinkertaista ja isommankin rasterin laskutoimitukset varmasti helpottuvat homattavasti. |
|
Virtaussuunta-rasterin avulla saatiin vihdoin tehtyä ensimmäinen hydrologinen mallinnus Basin-työkalulla, joka palautti rasterin kanjonin valuma-alueista. Ja jälleen pääsimme käyttämään yhtä Raster to… -työkaluista, jolla muunsimme rasterin polygoneiksi.
Valuma-alueissa oli paikoittain outouksia, joissa monta yhden pikselin levyistä valuma-aluetta kurkotti tason reunaan vieri vieressä. Oma päätelmäni tästä oli, että alueella kulkisi todellisuudessa leveämpi uoma, mutta koska mallinnuksemme on yksinkertaistus todellisesta maailmasta, jatkaa virtaus jokaisesta pikselistä vain yhteen suuntaan. Tästä johtuen leveämmät alueet pilkkoutuvat yhden pikselin levyisiksi janoiksi.
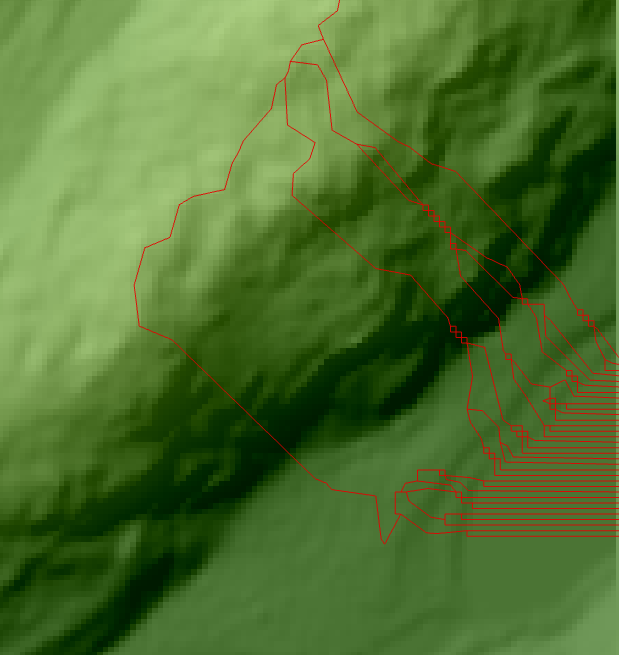
Valuma-alueiden outouksia
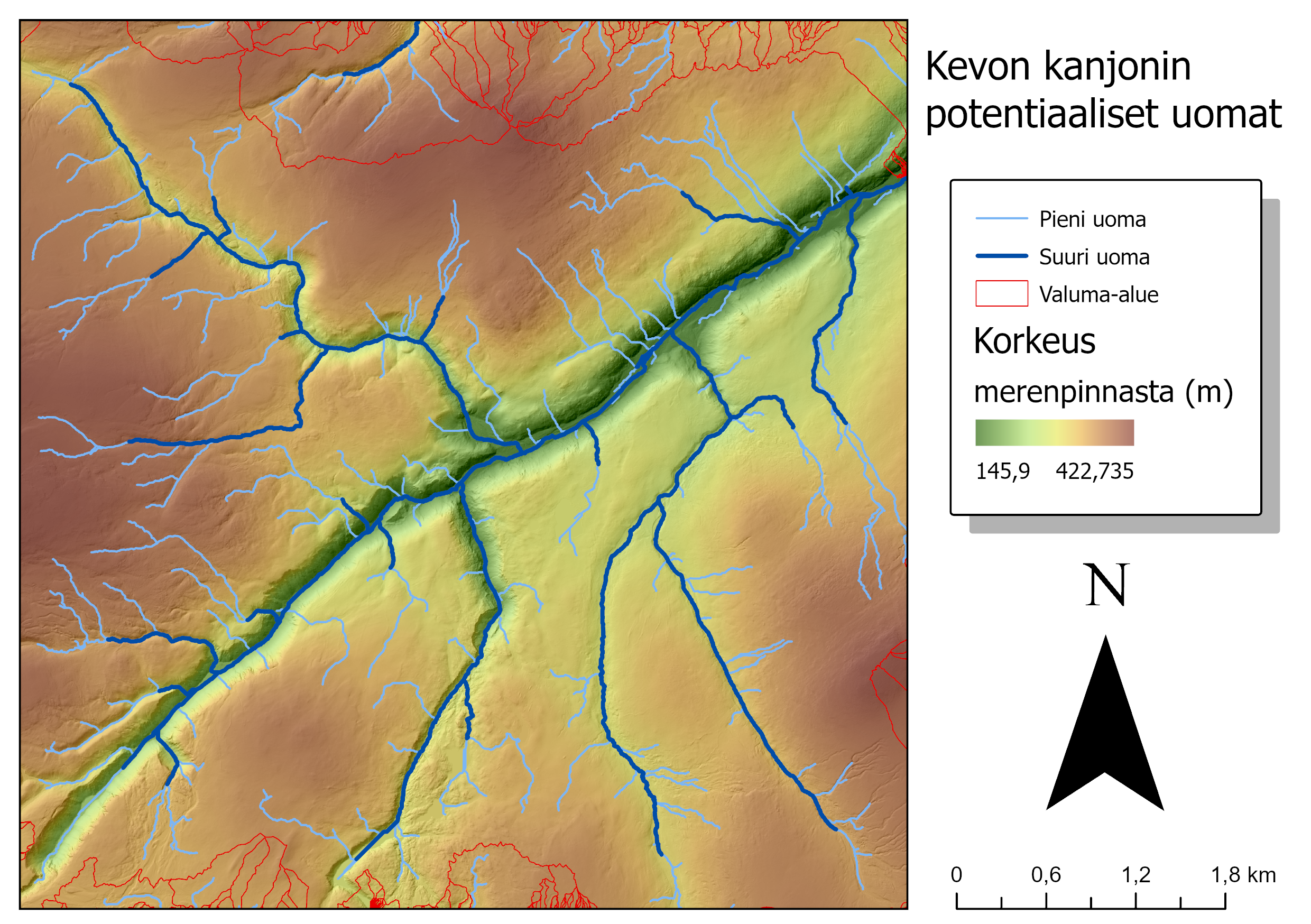
Toisena hydrologisena mallinnuksena selvitettiin alueen potentiaaliset uomat. Ensin luotiin rasteri, jossa laskettiin kullekkin pikselille, kuinka monesta muusta pikselistä siihen valuisi vettä. Koska koko korkeusrasterissa oli 9 miljoonaa pikseliä, syntyi uuteen rasteriin kaikkia arvoja nollan ja useamman miljoonan väliltä. Tästä rasterista tehtiin Reclassify-työkalulla muutama eri versio, joissa normalisoitiin kaikki arvot yhdeksi, jos ne ylittivät tietyn rajan ja muut arvot asetettiin nollaan. Näin saatiin kolmannella Raster to… -työkalulla muunnettua pikselijonot vektoreiksi, jotka kuvastavat potentiaalisia uomia.
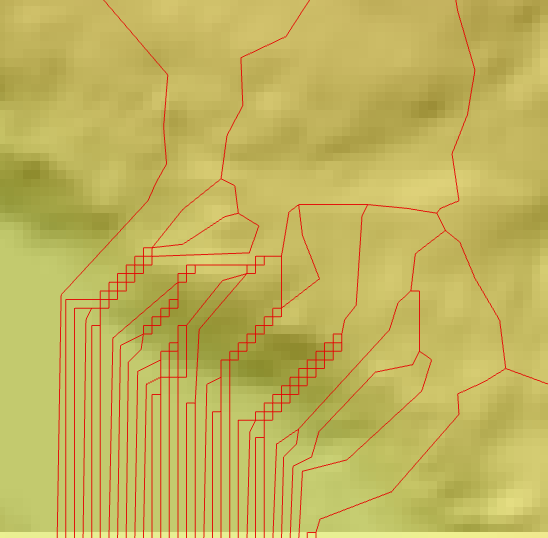
Tein normalisoinnin raja-arvoilla 100 000, 10 000 ja 1 000. Näistä korkein raja tuotti aineiston vain kaikista suurimmista uomista ja osa maastokartalla näkyvistä todellisista uomista jäi uupumaan. Keskimmäinen raja tuotti lähes kaikki maastokartalla näkyvät uomat ja loi jopa muutamia, joita ei maastokartan mukaan ole olemassa. Pienin raja tuotti jälleen valuma-alueista tuttuja yhden pikselin kokoisia outouksia.
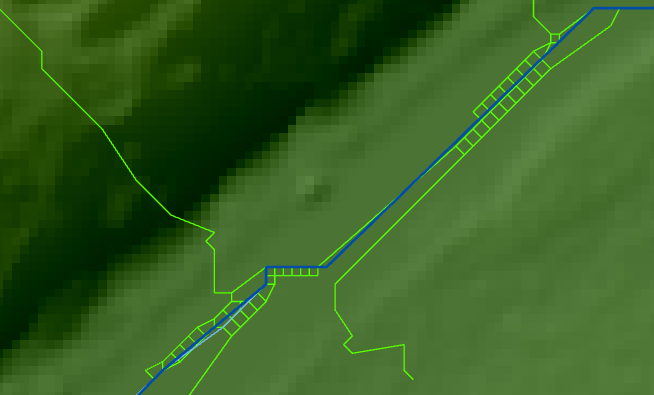
Raja-arvon 1 000 tuottamia outouksia
Näiden havaintojen perusteella päätin hyödyntää kahta ensimmäistä aineistoa lopullisessa visualisoinnissani. Lisäksi halusin kokeilla maastokartan hyödyntämistä Hillshade-tason tapaan blend-toiminnolla, jotta sain myös paikannimiä näkyviin kartalle. En kuitenkaan ollut aivan vakuuttunut lopputuloksesta, joten tein karttatulosteesta myös toisen version. Lukija tuomitkoon kumpi on parempi.

Viittaukset:
- Holopainen, M., Tokola, T., Vastaranta, M., Heikkilä, J., Huitu, H., Laamanen, R., Alho, P. (2015). Geoinformatiikka luonnonvarojen hallinnassa (7. julkaisu). Helsingin yliopiston metsätieteiden laitos